La gestión de excepciones es un punto siempre importante para garantizar que una aplicación se comporta de manera adecuada ante situaciones inesperadas.
Aquí tenéis una implementación de un “framework” muy simple, pero extensible, que nos permitirá normalizar la gestión de las excepciones en nuestro sistema.
La clase Work<T>:
public class Work<T>
{
private readonly Func<Task<T>> task;
private readonly ExceptionHandler exceptionHandler;
public Work(Func<Task<T>> task)
: this(task, new NoExceptionHandler())
{ }
public async Task<Result<T>> Run()
{
try
{
var result = await task();
return Ok(result);
}
catch (Exception ex)
{
exceptionHandler.Handle(ex);
return Error();
}
}
}
Nos permitirá ejecutar tareas asíncronas y gestionar las posibles excepciones que puedan ocurrir. Además, aprovechando el uso del patrón decorador con la interface ExceptionHandler, podremos personalizar el comportamiento de nuestro código cuando se de alguna excepción.
Incluso podemos crear un handler para gestionar esas típicas excepciones comunes que tenemos en nuestro proyecto y que repetimos una y otra vez por todos lados.
Hace algún tiempo que en el podcast de Aporreando Teclados hemos hablado bastante sobre Agile. Y no es raro que caigan en nuestras manos libros como “Actionable Agile Metrics for Predictability” y” When Will It Be Done” de Daniel S. Vacanti.
Spoiler:
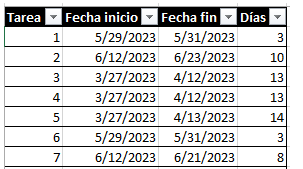
El autor nos indica que la lista de tareas realizadas en un proyecto de software es un generador de números aleatorios. Basta con monitorizar dos cosas:
El día en que se empieza a trabajar en esa tarea
El día en que se da por cerrada esa tarea
A partir de esas dos fechas, puedes obtener el número de días en las que se ha trabajado. Hace notar que si una tarea empieza y termina el mismo día, no significa que se haya tardado en cerrar cero días, sino que ese caso es un día, aunque haya sido una, dos u ocho horas. Con esto podemos obtener una tabla como la del ejemplo:
En la obra se explica que la columna de Días son números totalmente aleatorios con una sutileza: Son aleatorios sí, pero indican lo que ha ocurrido en la realidad. Y eso es lo importante, ya que con esta información se puede saber algo muy importante:
Cycle Time o tiempo en el que se tarda desde que se empieza una tarea hasta que finalmente se termina.
Una imagen vale más que mil palabras
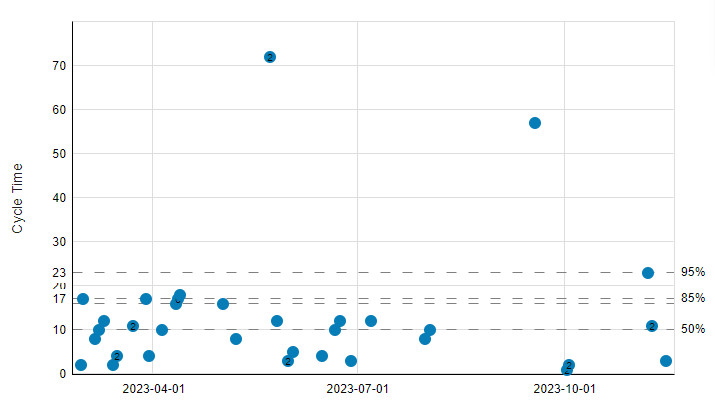
Esta información podemos visualizarla de una forma más amigable, usaremos un gráfico de dispersión (Scatter plot). En el eje horizontal se muestra el devenir de la vida (el tiempo) y en el eje vertical el Cycle Time de todas las tareas:
Se han marcado diferentes percentiles teniendo en cuenta toda la información de lo que ha pasado en realidad: 95, 85, 50. ¿Porqué?
Los Percentiles
Una primera observación es que parece que hay más tareas por encima del percentil 50 que por debajo. Es decir, hay más tareas que tardan en cerrarse más de 10 días que menos. Por tanto, si nuestros sprints son de 2 semanas, es decir de 10 días, ¿tiene sentido ese tamaño de sprint?
Si en ese sprint decimos que vamos a hacer una tarea, da igual los puntos de historia que tenga, tenemos una probabilidad más alta de NO terminarla que de terminarla.
¿Qué acción podemos tomar? Subir el tamaño de los sprints a … 17 días que es lo que nos está indicando el percentil 85 sería una opción.
Con esto, dada cualquier tarea que añadamos al sprint, tendríamos un 85% de probabilidades de terminarla.
Esta decisión de incrementar el tamaño del sprint es cosa de cada uno, y para nada estoy sugiriendo que la regla sea: el tamaño del sprint debe estar en el percentil 85. Un sprint de 17 días suena raro, muy raro.
Datos más datos
Una segunda observación es que hay dos puntos que están muy lejos del percentil 95. Podríamos decir que son “outliers” u “outsiders” y no hacerles mucho caso, pero eso es un error. Por muy alejados que estemos del percentil 95, esos puntos son hechos reales que han ocurrido con esas tareas. Y ya en los libros nos adelanta que las predicciones serán tan buenas como buenos sean los datos de los que partimos, si quitamos esos outsiders, quitamos bastante información.
¿Puedes imaginar una predicción meteorológica en la que no se tenga en cuenta el tiempo que hizo ayer? De hecho, es un ejemplo con el que parte el segundo libro, When Will It Be Done, y es que es necesario conocer toda la información anterior para poder hacer una predicción.
Pero una predicción no es lo que va a ocurrir, sino lo que va a ocurrir con cierta probabilidad.
Simulando que es gerundio
El libro no va sobre cómo hacer simulaciones, eso ya se estudia y ha demostrado su valía en la predicción meteorológica e incluso en los experimentos realizados en Los Alamos mientras se creaba la primera bomba nuclear. El sistema que se usa es “Simulación Monte Carlo” pero este humilde blog tampoco se va a centrar en cómo se hace, ya que lo que nos importa es la información que esas simulaciones nos van a proporcionar.
Para los datos del ejemplo, esta simulación, iterada 10.000 veces, para intentar predecir cuándo se terminarán 20 tareas más nos da el siguiente resultado:
Con un 50% de probabilidad, las 20 tareas estarán el 14 de Marzo de 2024
Con un 70% de probabilidad, las 20 tareas estarán el 2 de Abril del 2024
Con un 85% de probabilidad, las 20 tareas estarán el 21 de Abril del 2024
Con un 95% de probabilidad, las 20 tareas estarán el 16 de Mayo del 2024
Curiosidad
Fijaos que no hemos hablado de tamaño de tareas ni nada por el estilo; por tanto, da igual si están estimadas o no esas tareas, la realidad al final siempre se acaba imponiendo, y parece que no tiene sentido estimar las tareas, ojo, para un proyecto en marcha, con varios sprints a sus espaldas.
Aunque parezca mentira, no hace falta usar mucha información para empezar a hacer estas simulaciones, tendría que leer otra vez los libros, pero me resuena en la cabeza que con 11 mediciones de tareas que hayas realizado suele ser suficiente para empezar.
A medida que vayamos avanzando en nuestro proyecto, cerrando tareas, estas simulaciones deben ir rehaciéndose. Como la predicción del huracán que decía al principio, cada día que pasa hay que ir actualizando la predicción.
Ganando pasta
Haciendo de décimo hombre, y criticar por criticar, los libros parecen un panfleto publicitario de la herramienta que usan para hacer estos cálculos, que tenéis disponible en https://actionableagile.com/ (Las capturas de pantalla y las simulaciones que he hecho se han sacado de ahí con el plan free)
Los libros y este post son una lista de puntos de porqué debemos empezar a medir ese cycle time, hacer simulaciones y actuar en consecuencia con la información real que tenemos lo antes posible.
Cuando llegamos a la tercera sección empezamos a escribir tests de interfaces de usuario con Espresso. La primera vez que lo ejecutamos impresiona ver cómo nuestra app comienza a ejecutarse y a hacer cosas sola. Aunque está archivado como un codelab avanzado, aún se puede exprimir un poco más introduciendo el patrón Page Object.
Patrón Page Object
El sentido del page object es esconder todo el código necesario para replicar los pasos que hay que hacer para navegar por la app, realizar acciones como un usuario etc… y ofrecer una interfaz limpia que nos permita escribir tests más semánticos y mantenibles.
Para verlo en acción, hemos usado el propio código de la solución final del codelab que podéis encontrar aquí:
Comenzamos añadiendo esta clase Page que hace gran parte de la magia. La añadimos al source set “androidTest”:
open class Page {
companion object {
inline fun <reified T : Page> on(): T {
return Page().on()
}
}
inline fun <reified T : Page> on(): T {
val page = T::class.constructors.first().call()
page.verify()
//Thread.sleep(500) //To give time when asynchronous calls are invoked
return page
}
open fun verify(): Page {
// Each subpage should have its default assurances here
return this
}
fun back(): Page {
Espresso.pressBack()
return this
}
}
Al final, esta clase se usa para poder definir una API fluida que nos permitirá organizar el código que necesitamos para navegar, realizar acciones, comprobar cosas en las páginas, vistas, etc. Prestad especial atención a la función verify. Esta función se usa para comprobar si la página que queremos se ha cargado.
Vamos a añadir nuestro primer test. Vamos al archivo AppNavigationTest.kt y añadamos un nuestro test que añadirá una nueva tarea a la app:
@Test
fun createNewTask() {
// Start up Tasks screen
val activityScenario = ActivityScenario.launch(TasksActivity::class.java)
dataBindingIdlingResource.monitorActivity(activityScenario)
// When using ActivityScenario.launch, always call close()
activityScenario.close()
}
Vamos a añadir las clases TasksPage y AddTaskPage en el mismo paquete donde está nuestro PageObject:
class TasksPage : Page() {
override fun verify(): TasksPage {
onView(withId(R.id.tasks_container_layout))
.check(matches(isDisplayed()))
return this
}
fun tapOnAddButton(): TasksPage {
onView(withId(R.id.add_task_fab)).perform(ViewActions.click())
return this
}
fun tapOnEditTask(): TasksPage {
onView(withId(R.id.edit_task_fab)).perform(ViewActions.click())
return this
}
fun checkAddedTask(testTask: Task): TasksPage {
onView(withText(testTask.title))
return this
}
}
class AddTaskPage: Page() {
override fun verify(): AddTaskPage {
Espresso.onView(withId(R.id.add_task_title_edit_text))
.check(ViewAssertions.matches(isDisplayed()))
return this
}
fun addTask(task: Task):AddTaskPage{
onView(withId(R.id.add_task_title_edit_text))
.perform(clearText(), typeText(task.title))
onView(withId(R.id.add_task_description_edit_text))
.perform(clearText(), typeText(task.description))
onView(withId(R.id.save_task_fab)).perform(click())
return this
}
}
En estas clases está todo el código de Espresso que necesitamos para hacer las interacciones, pero bien ordenadito y recogidito. Si no lo hiciéramos así, terminaríamos con un test muy largo, con todos esos métodos de Espersso en un solo test, con lo que tendríamos un test difícil de leer y mantener. Además, si hiciésemos más tests de este tipo, tendríamos bastante código repetido entre los tests.
Si ejecutamos el test, el resultado será similar a:
Veamos el test equivalente sin usar el patrón PageObject:
@Test
fun createNewTaskWithoutPageObject(){
val activityScenario = ActivityScenario.launch(TasksActivity::class.java)
dataBindingIdlingResource.monitorActivity(activityScenario)
val task= Task("title", "description")
//check tasks page open
onView(withId(R.id.tasks_container_layout))
.check(matches(isDisplayed()))
//tap on add button
onView(withId(R.id.add_task_fab)).perform(ViewActions.click())
//check task page is open
onView(withId(R.id.add_task_title_edit_text))
.check(ViewAssertions.matches(isDisplayed()))
//add task
onView(withId(R.id.add_task_title_edit_text))
.perform(ViewActions.clearText(), ViewActions.typeText(task.title))
onView(withId(R.id.add_task_description_edit_text))
.perform(ViewActions.clearText(), ViewActions.typeText(task.description))
onView(withId(R.id.save_task_fab)).perform(click())
//check task page is open
onView(withId(R.id.tasks_container_layout))
.check(matches(isDisplayed()))
//check added task
onView(withText(task.title))
// When using ActivityScenario.launch, always call close()
activityScenario.close()
}
¿Qué test preferirías mantener?
Los beneficios de usar este patrón para crear test de interfaz de usuario son:
Test semánticos: Como podemos ver, el código es muy descriptivo, está escrito como si fuera una novela.
Mantenimiento:
Cada vez que cambie la interfaz, sólo cambiaremos aquellas páginas que se han visto afectados. Pero con esta arquitectura, es fácil encontrarlos, y es más fácil averiguar porqué ha fallado.
Añadir nuevos test es más rápido ya que no tendremos que estar duplicando código.
Resumen
El patrón Page Object está muy extendido a la hora de hacer tests de UI en otras plataformas como Java, JavaScript, C#. Una vez que se entiende, como me pasa a mí, algo hace clic en la cabeza. Y es muy fácil de aplicar.
Una de las primeras cosas que recomiendo e intento hacer cuando empezamos un desarrollo es configurar las builds de integración y despliegue continuos desde el minuto 0. Hay que tener en cuenta que tiempo que tarda en ejecutarse una build es, cómo decirlo, oro.
Y es que tras configurar una github action para un proyecto de iOS me sorprendió la cantidad de tiempo que tardaba en ejecutarse… Casi 30 minutos. Así que tocaba “arremangarse” y buscar cómo optimizarlo.
Da igual si lo haces con githubactions, Jenkins, Teamcity, Azure Devops, etcc … Hay que hacer dos cosas:
Cachear el contenido de “derivedData”
Busca la forma de cachear ese directorio, de lo contrario, en cada build que se ejecute se descargará y compilará todas las referencias que tengas en tu proyecto.
Aquí os pongo cómo puedes hacerlo si usas githubactions:
Estamos cacheando ese directorio, que en mi caso está en la raíz del proyecto porque cuando ejecuto el comando xcodebuild, le indico que use ese directorio como derivedDataPath. Esto se consigue añadiendo al comando xcodebuild el parámetro “-derivedDataPath ./DerivedData”, o el directorio que quieras. Si no se lo indicas, el directorio derived data se encuentra en /Library/Developer/Xcode/DerivedData/”miproyecto”
Os recomiendo que sólo cacheéis los directorios de Build y SourcePackages, ya que son los que contienen el código y el resultado de las compilaciones de las dependencias. El resto es para cache de símbolos logs, resultados de tests.. que si los incluís en la cache se va a estar invalidando en cada build y la volverá a guardar… y eso aunque no es mucho, es tiempo… y el tiempo es…
Prestad especial atención también a cómo se generan las claves para la cache, estamos aprovechando el hash del archio podfile.lock para generar una nueva entrada en la cache cuando se añada un nuevo paquete.
Añadir un parámetro a xcodebuild.
El segundo punto importante y que no se nos debe olvidar es pasarle al comando xcodebuild el parámetro:
Seguramente por mi “L” de desarrollador iOS he estado un día entero investigando porqué después de añadir los paquetes de Firebase Crashlytics y FirebaseAnalytics, la pipeline que genera el IPA empezó a fallar. Compilaba el paquete, hacia el Archive, pero cuando hacía el export, termina dando el error Error Domain=IDEFoundationErrorDomain Code=1 “IPA processing failed” UserInfo={NSLocalizedDescription=IPA processing failed}
Despues de un día intentando reproducirlo en local y viendo que todo funcionaba perfectamente me dí cuenta que la versión del sdk iphoneos que tiene instalada la máquina de azure era la 14.4. y yo en local lo tengo todo a la última….
Jugando a detective colombo, pensé “¿y si no le gusta que halla añadido la referencia a traves del package manager?” … pues por probar y ya que no se me ocurría nada más, instalé las dependencias como paquetes POD … y ALELUYA!!!
Por fin me genera el ipa como $Deity manda
Espero que le sirva a alguien que como yo aún va con la L
Sólo quería dejar aquí presente algo que he estado haciendo y es aprender ha desarrollar aplicaciones nativas en iOS con Swift. Y para eso aquí tenéis un repo donde voy metiendo cositas de vez en cuando: https://github.com/juanlao/BenfordsLaw
El objetivo de este repositorio es aprender plataformas nuevas e ir descubriendo los intríngulis de cada una de ellas con TDD (Test Drive Development) que tengo la sensación de que no va a ser un mal camino para aprender los entresijos de un nuevo lenguaje/plataforma. Y además seguro que aprendo cosas nuevas sobre cómo hacer tests unitarios 🙂
Cuando nos surge la necesidad de montar una máquina virtual en Azure resulta interesante hacer que esa máquina se apague y se encienda automáticamente en los horarios que la solemos usar, típicamente en horario de oficina.
Recientemente me ha sido necesario averiguar cual es la última versión de MSBuild que está instalada en el sistema. Hacer la comprobación de que existe un archivo en el path por defecto del tipo “C:Program Files (x86)Microsoft Visual Studio2017CommunityMSBuild15.0Bin” no es buena idea. Ya que por ejemplo puede que el usuario no lo haya instalado en ese directorio,
En StackOverflow tenéis una solución bastante interesante.
Los pasos:
Instalar el paquete de Nuget Microsoft.Build.Framework.
Las versiones 4.0, 12.0 y 14.0 dejan una entrada en el registro con el path:
Para la última versión, la 15.0 hay que hacer algo más ya que esta última versión no deja huella en el registro.
Es necesario añadir el paquete Nuget: Microsoft.VisualStudio.Setup.Configuration.Interop
Y con este código es posible buscar en dónde está:
var query = new SetupConfiguration();
<pre><code> var query2 = (ISetupConfiguration2)query;
var e = query2.EnumAllInstances();
var helper = (ISetupHelper)query;
int fetched;
var instances = new ISetupInstance[1];
do
{
e.Next(1, instances, out fetched);
if (fetched &gt; 0)
{
var instance = instances[0];
var instance2 = (ISetupInstance2)instance;
var state = instance2.GetState();
// Skip non-complete instance, I guess?
// Skip non-local instance, I guess?
// Skip unregistered products?
if (state != InstanceState.Complete
|| (state &amp; InstanceState.Local) != InstanceState.Local
|| (state &amp; InstanceState.Registered) != InstanceState.Registered)
{
continue;
}
var msBuildComponent =
instance2.GetPackages()
.FirstOrDefault(
p =&gt;
p.GetId()
.Equals(&quot;Microsoft.Component.MSBuild&quot;,
StringComparison.InvariantCultureIgnoreCase));
if (msBuildComponent == null)
{
continue;
}
var instanceRootDirectory = instance2.GetInstallationPath();
var msbuildPathInInstance = Path.Combine(instanceRootDirectory, &quot;MSBuild&quot;, msBuildVersion, &quot;Bin&quot;, &quot;msbuild.exe&quot;);
if (File.Exists(msbuildPathInInstance))
{
return msbuildPathInInstance;
}
}
} while (fetched &gt; 0);
</code></pre>
Jugando con este código ya podemos ver de una forma más adecuada dónde están instaladas las versiones de MSBuild.
En el ciclo de vida de un equipo Scrum es normal que se vayan incorporando personas al equipo con el tiempo, pero esto hay que gestionarlo de alguna forma.
Veremos una dinámica que puede ayudarnos a gestionar esto.
Si implementáis Scrum, puede que llegue un día en que la daily se alarga demasiado, pero no porque cada miembro del equipo se alargue en qué hizo, qué va a hacer y qué le tiene bloqueado, sino simplemente somos ya muchos porque se van incorporando a la plantilla más personas. Empieza a parecer necesario dividir la daily o algo así, como la daily es por equipo, parece ser buena idea dividirnos en dos equipos, pero ¿cómo lo hacemos?
Mitosis Scrum
Hace tiempo, no recuerdo dónde, leí una dinámica que se basa en el principio de “multidisciplinaridad”. Se supone que un equipo debe ser autosuficiente para llevar a cabo cualquier proyecto que le llegue, por lo tanto, debe ser multidisciplinar. La cosa consiste en coger a todas las personas que forman parte del equipo que se va a dividir en una habitación y se vayan a la parte izquierda o derecha de la sala atendiendo al criterio de “multidisciplinaridad” para formar dos equipos diferentes.
Por ejemplo, si yo me considero una persona buena en crear interfaces de usuario y sé que Pepito también, pues no me pondré con Pepito en su mismo equipo, me iré al otro.
Una vez que tenemos los dos equipos, tomamos una foto de ambos y volvemos a repetir el proceso varias veces. Supongo que cinco configuraciones diferentes parece ser un buen número.
De esta forma, tenemos muy rápidamente, varias configuraciones posibles de equipos multidisciplinares con las personas que lo van a formar.
Lo que queda es elegir las definitivas. ¿Cómo lo hacemos?, como hacemos en la retrospectiva, cada miembro tiene tres votos y puede elegir tres combinaciones, el más votado, es la configuración elegida y la mitosis de un equipo se ha producido.
Esta dinámica no recuerdo dónde la leí, y ni si tiene nombre, ¿tiene nombre? ¿la habéis usado? ¿Qué tal os ha ido de haberla usado? ¿Cuántas configuraciones obtenéis antes de elegir una?